|
I am currently part of the Machine Learning team at Latent AI, accelerating AI on the edge. I am a recent graduate from Carnegie Mellon University, specializing in AI/ML systems in Electrical and Computer Engineering. I graduated as a Gold medalist from the National Institute of Technology, Tiruchirappalli in Electronics and Communication Engineering in 2022. I was affiliated with the Max Planck Institute of Informatics, Saarbrücken, funded by the DAAD-WISE Scholarship. I'm a recipient of the Indian Academy of Sciences Research Fellowship, the prestigious Dr. A.L. Abdussattar Memorial Award, the Sri Janardhana Iyengar Memorial Award, and the Graphics Replicability Stamp Award. Outside of research, I'm open to anything to do with Sustainability and Mental Health. Scroll down to know more! |

|
|
|
During my time at Carnegie Mellon University, I worked at the AirLab (Robotics Institute) on large-scale real-world scene understanding for urban robots. My research primarily explores the intersection of computer vision and efficient deep learning. I collaborated with researchers at the Medical Mechatronics Lab, National University of Singapore, as a Research Assistant on Graph-based Deep Reasoning and Surgical Scene Understanding. As a Deep Learning Engineer at AIMonk Labs Pvt. Ltd., I worked in a team to build Neuralmarker, transforming businesses with Computer Vision. I received a recommendation from Foxconn Country Head, Josh Foulger, to work with their Intelligent Systems Team on prototyping. Previously, I was affiliated with the Advanced Geometric Computing Lab and the Shakti Group at the Indian Institute of Technology, Madras, supervised by Dr. M. Ramanathan and Dr. V. Kamakoti. I also worked on Deep Generative Modelling of Real-time Wireless Communication Channels using UAVs with Dr. E.S. Gopi at NIT Trichy, and Dr. Nalin Jayakody at the Tomsk Infocomm Lab. |
|
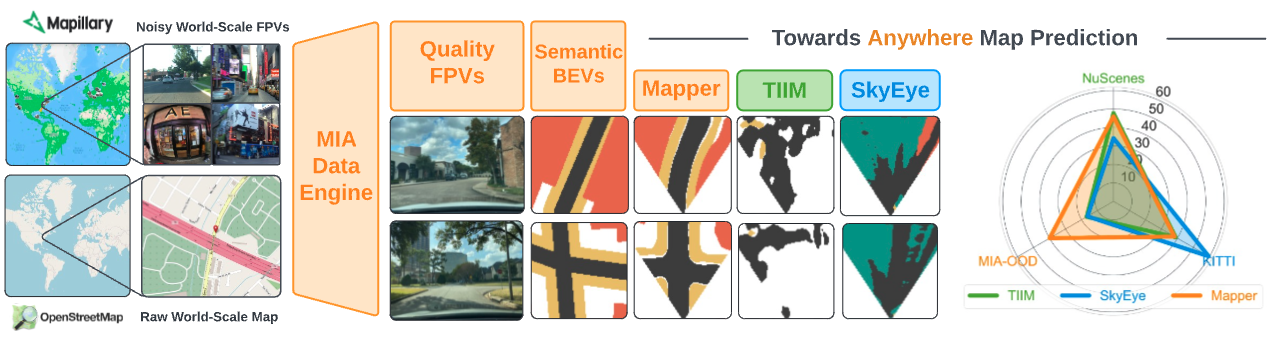
Cherie Ho*, Jiaye Zou*, Omar Alama*, Sai Mitheran Jagadesh Kumar, Benjamin Chiang, Taneesh Gupta, Chen Wang, Nikhil Keetha, Katia Sycara, Sebastian Scherer Neural Information Processing Systems (NeurIPS), 2024 [Dataset and Benchmark Track] Webpage / arXiv Top-down Bird's Eye View (BEV) maps are essential for ground robot navigation, yet current methods for predicting BEV maps from First-Person View (FPV) images lack scalability. We introduce Map It Anywhere (MIA), a data engine leveraging Mapillary and OpenStreetMap to curate a diverse dataset of 1.2 million FPV-BEV pairs. Our model trained on MIA's dataset significantly outperforms existing methods, demonstrating the effectiveness of large-scale public maps for enhancing BEV map prediction and autonomous navigation. |
|
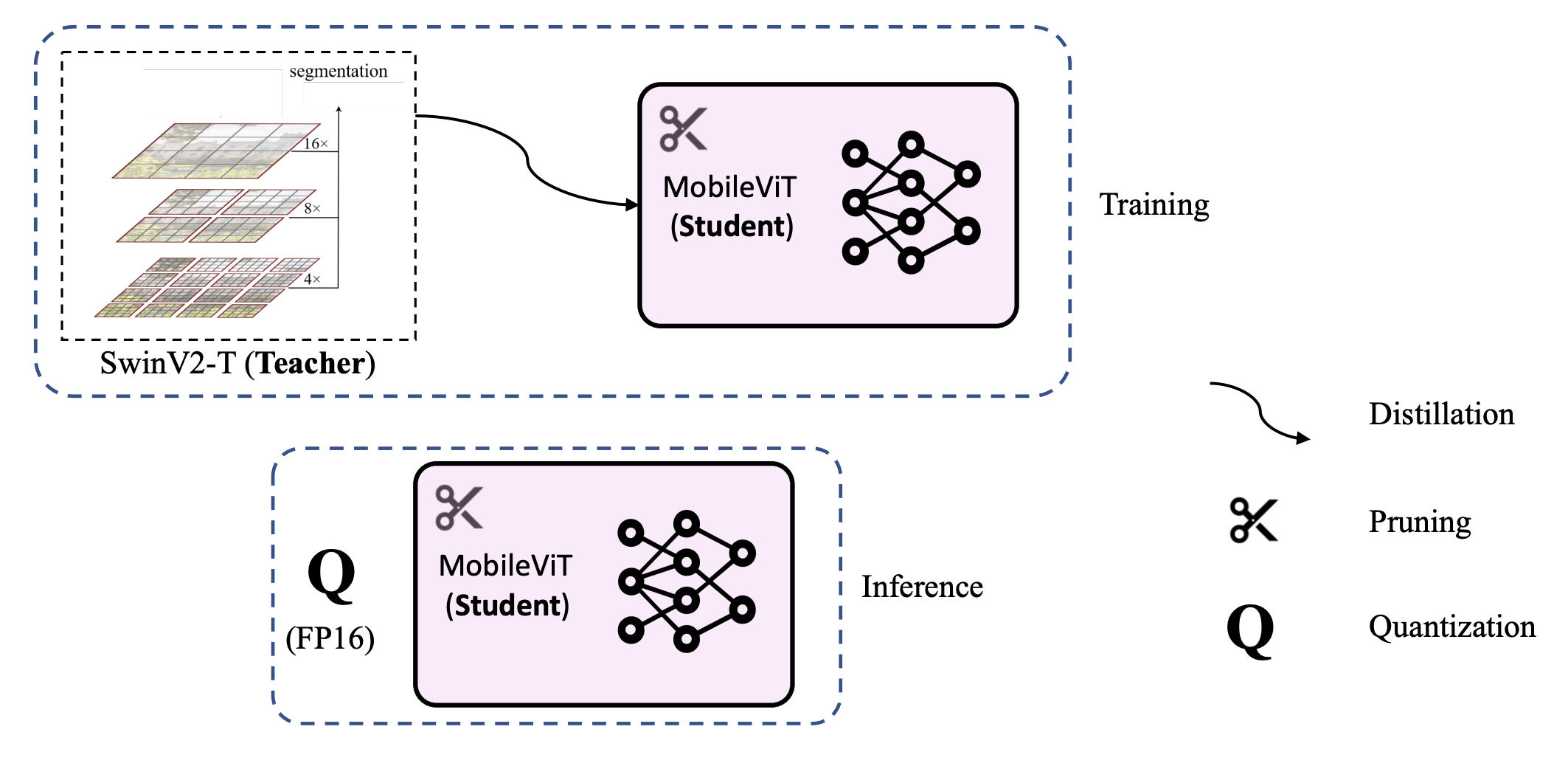
Youn, Eric and Mitheran, Sai and Prabhu, Sanjana and Chen, Siyuan arXiv / Paper Our work introduces a framework for compressing Vision Transformer models for efficient segmentation, with a focus on enabling deployment on resource-constrained devices like the NVIDIA Jetson Nano (4GB). Our approach combines structured pruning, distillation from a stronger teacher, and quantization strategies to significantly reduce memory usage and inference latency while maintaining high segmentation accuracy and mean IoU. This allows for the rapid deployment of Vision Transformers on the edge. |
|
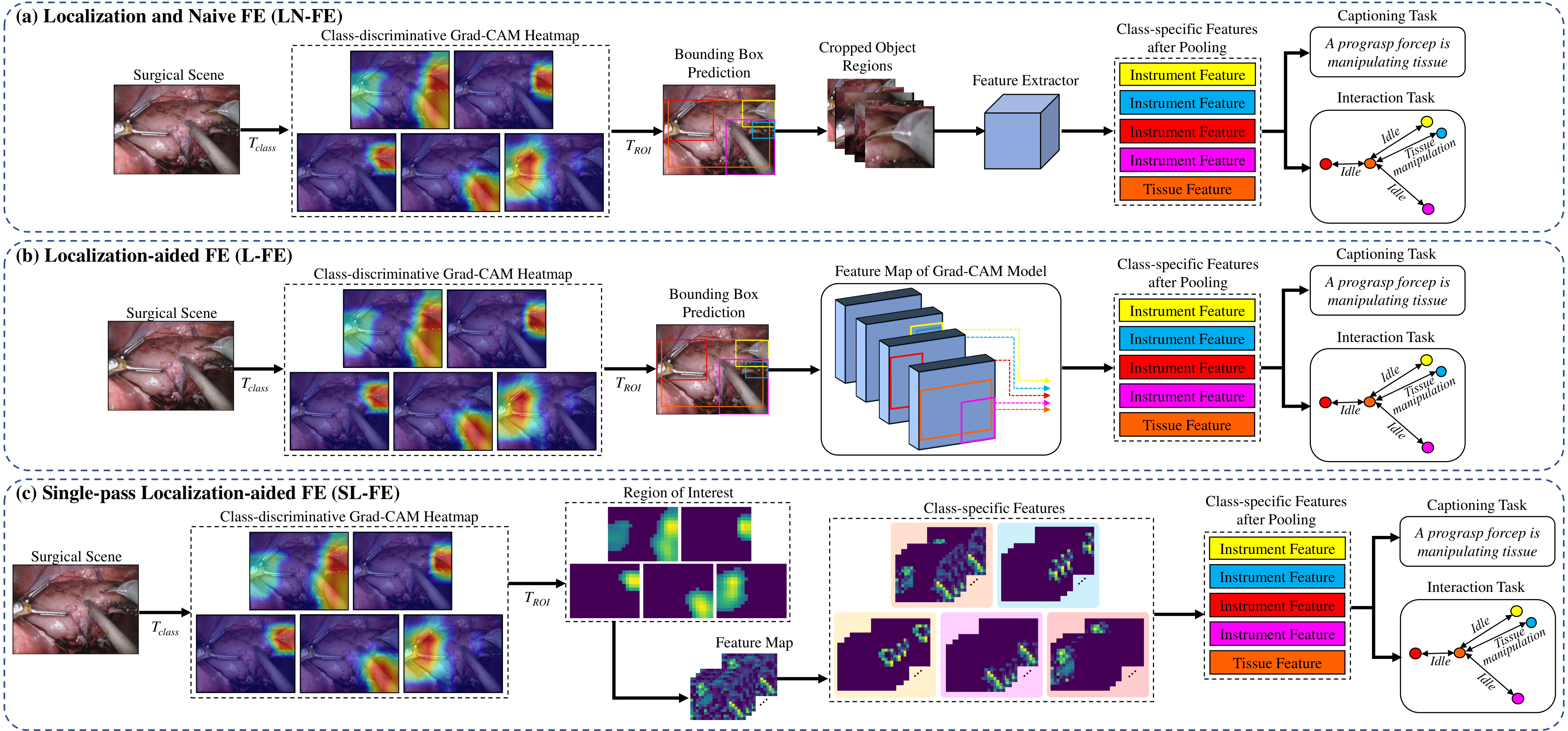
Pang, Winnie and Islam, Mobarakol and Mitheran, Sai and Seenivasan, Lalithkumar and Xu, Mengya and Ren, Hongliang ICRA, 2023 and IEEE RA-L Code / Paper We develop a detector-free gradient-based localized feature extraction approach for end-to-end model training in surgical tasks like report generation and tool-tissue interaction graph prediction. By using gradient-based localization techniques (e.g., Grad-CAM) to extract features directly from discriminative regions in classification models' feature maps, we eliminate the need for object detection or region proposal networks. Our approach enables real-time deployment of end-to-end models for surgical downstream tasks. |
|
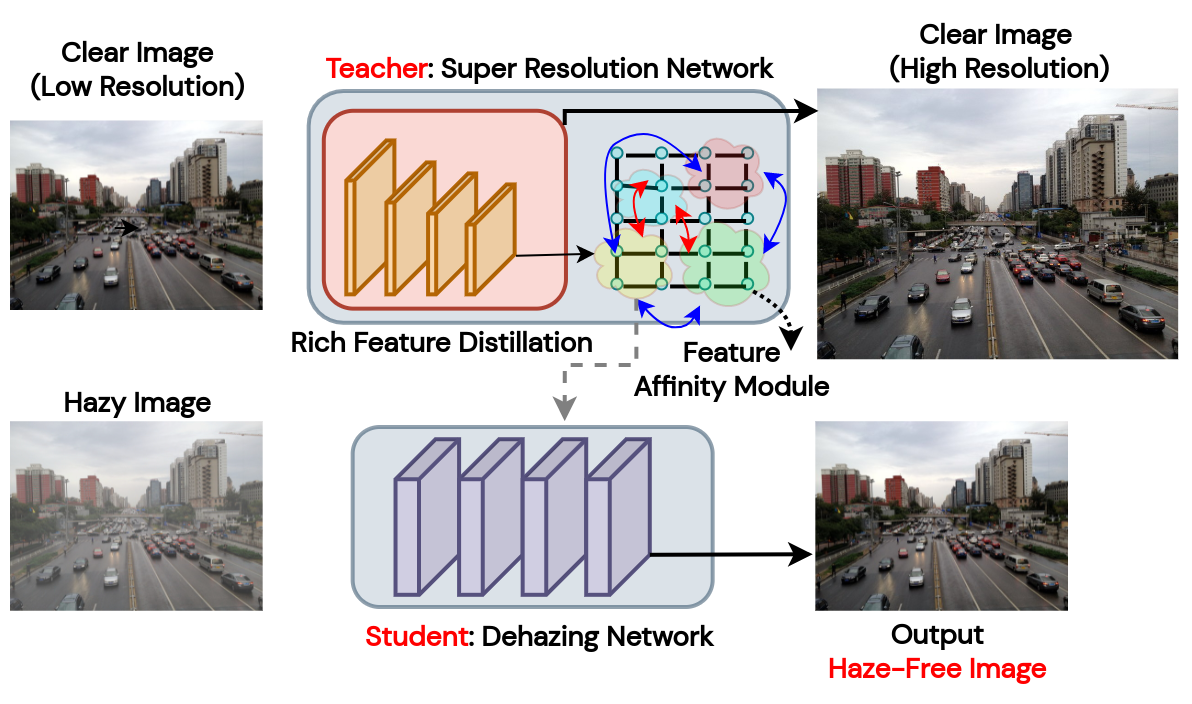
Mitheran, Sai and Suresh, Anushri and P Gopi, Varun Optik, Elsevier Code / arXiv / Paper This work introduces a simple, lightweight, and efficient framework for single-image haze removal, exploiting rich “dark-knowledge" information from a lightweight pre-trained super-resolution model via the notion of heterogeneous knowledge distillation. |
|
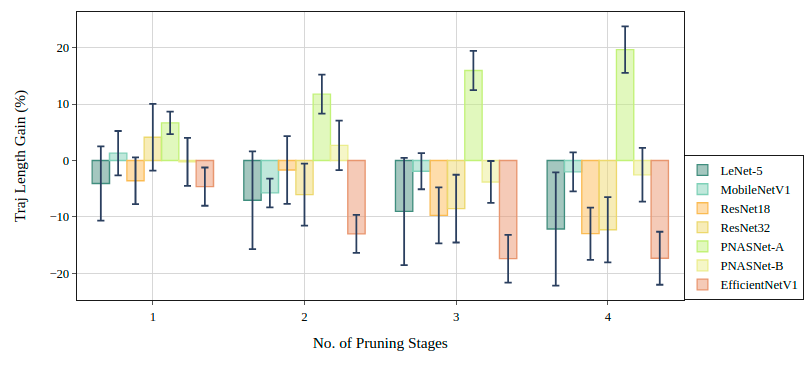
Sahu, Surya Kant and Mitheran, Sai and Mahapatra, Ritul ICML, 2022 (HAET Workshop) arXiv / Paper The Lottery Ticket Hypothesis (LTH) states that for a reasonably sized neural network, there exists a subnetwork within the same network that, when trained from the same initialization, yields no less performance than the dense counterpart. We investigate the effect of model size and the ease of finding winning tickets. Through this work, we show that winning tickets is in-fact, easier to find for smaller models. |
|
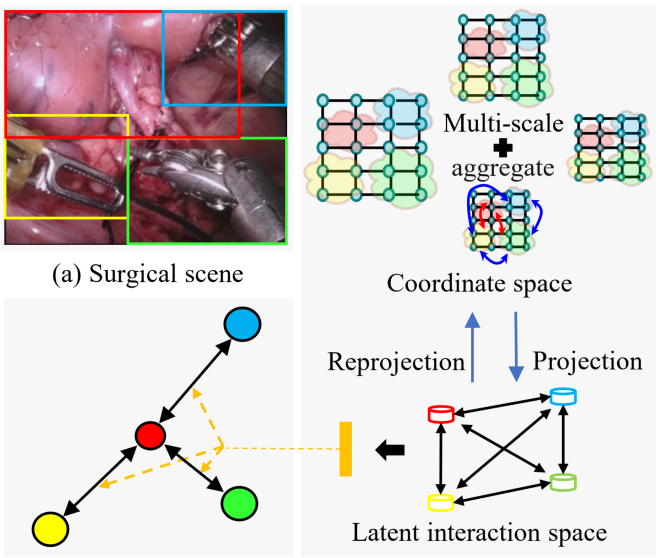
Seenivasan, Lalithkumar* and Mitheran, Sai* and Islam, Mobarakol and Ren, Hongliang ICRA, 2022 and IEEE RA-L [SOTA, Endovis18] Code / arXiv / Paper This paper introduces a globally-reasoned multi-task surgical scene understanding model capable of performing instrument segmentation and tool-tissue interaction detection. |

|
Sahu, Surya Kant and Mitheran, Sai and Kamdar, Juhi and Gandhi, Meet AAAI, 2022 (DSTC10 Workshop) [SOTA, Keyword Spotting] Code / Paper In this work, we introduce an architecture, Audiomer, where we combine 1D Residual Networks with Performer Attention to achieve state-of-the-art performance in Keyword Spotting with raw audio waveforms, out-performing all previous methods while also being computationally cheaper and parameter-efficient. |
|
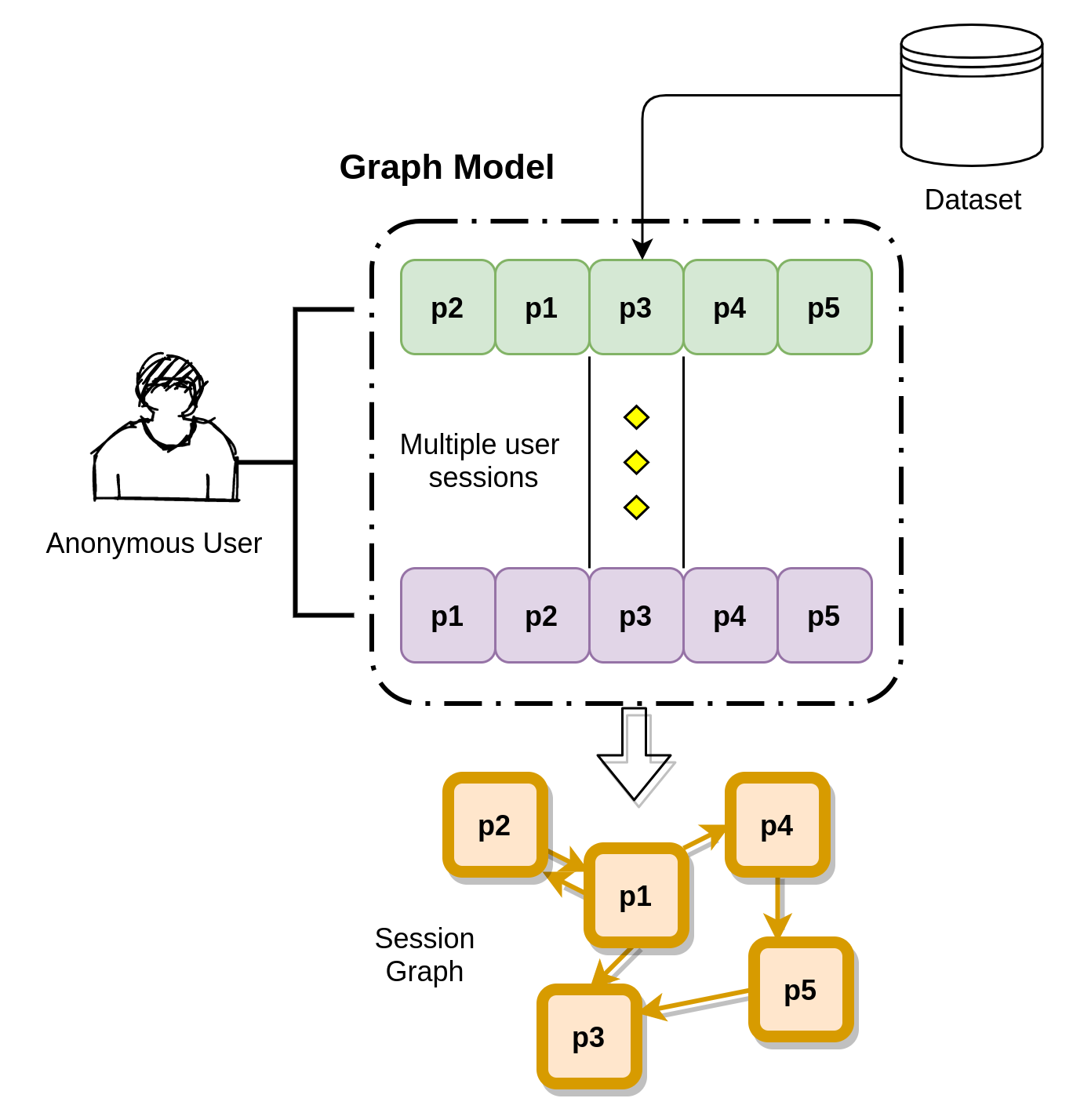
Mitheran, Sai and Java, Abhinav and Sahu, Surya Kant and Shaikh, Arshad AISP, 2022 Paper / Code / arXiv We propose using a Transformer in combination with a target attentive GNN, which allows richer Representation Learning. We outperform the existing methods on real-world benchmark datasets. |
|
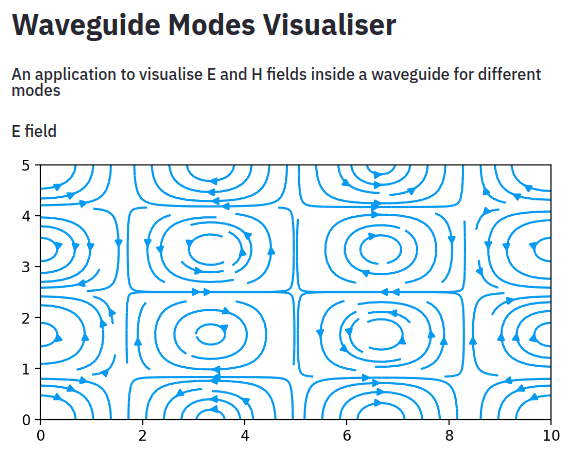
Mitheran, Sai and T N, Ram and S, Raghavan IEEE Microwave Magazine 2022, Microwaves 101, Recent Trends on Metamaterial Antennas for Wireless Applications and Deep Learning Techniques, 2021 Paper / Application / Microwaves 101 This article presents the procedure and results of a web application made to visualize field lines of Electric and Magnetic waves inside a waveguide. We propose a first-of-the-kind Graphical User Interface for waveguide visualization as a public resource. |
|
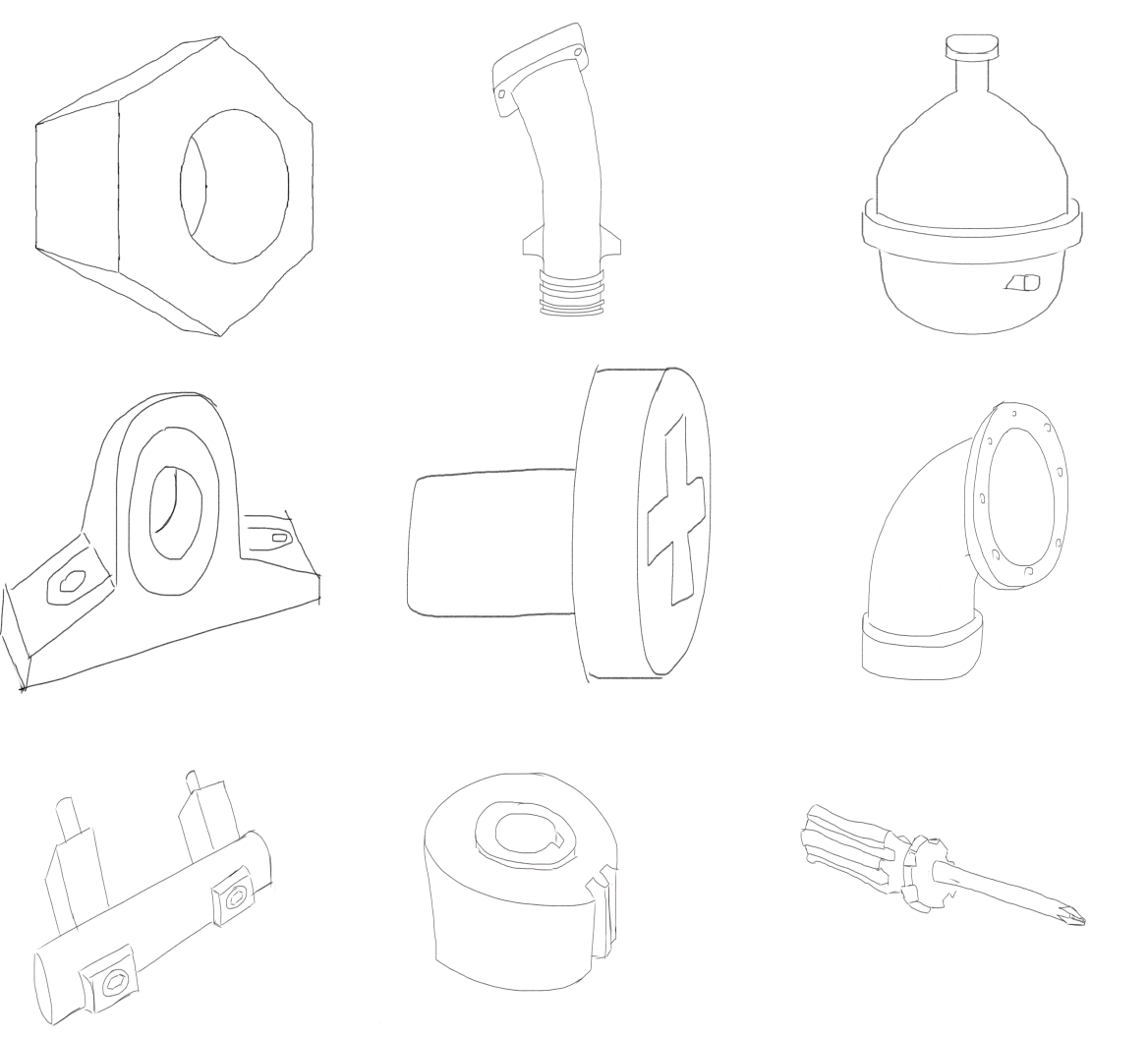
Manda, Bharadwaj and Dhayarkar, Shubham and Mitheran, Sai and V.K, Viekash and Muthuganapathy, Ramanathan 3DOR, 2021 and Computers & Graphics Journal Project Page / Paper We introduce the CADSketchNet dataset, an annotated collection of sketches of 3D CAD models, which is intended to enhance the research on developing AI-enabled search engines for 3D CAD models. We also evaluate the performance of various retrieval systems. Many experimental models are constructed and tested on CADSketchNet. |
|
|
 |
Student Volunteer, ICLR 2021 |

|
Student Volunteer, ICML 2021 |
|
|
|
|
|
|

|

|

|

|

|
|
|

|

|

|

|